

Pearson Correlation Score
Hello everyone, in our last Machine Learning tutorial we learnt about that how we can use Euclidean Distance formula to find out similarity among people. In this tutorial we learn a new way to do the same thing but in a bit complex or rather I should say in advanced manner. We will use Pearson Correlation Score for calculating similarity among people.
It has one major difference in the result being generated by it, in comparison to Euclidean Distance, that even if the distance between the values of fruits provided by two persons is high, but if it is consistent, that is difference is nearly is consistent through out all fruits, then Pearson Correlation Score will mark both persons highly similar or totally same.
| Mango | Banana | Strawberry | Pineapple | Orange | Apple | |
| John | 4.5 | 3.5 | 4 | 4 | ||
| Martha | 2.5 | 4.5 | 5 | 3.5 | ||
| Mathew | 3.75 | 4.25 | 3 | 3.5 | ||
| Nick | 4 | 3 | 4.5 | 4.5 |
For example in the above data if we look at ‘John’ and ‘Martha’ the distance between the fruits between them is nearly same, as a result Pearson Correlation Value will be around ‘1’ for them.
Theory behind Pearson Correlation Score
We will calculate Pearson Correlation Score only for those fruits which are common for both the persons.
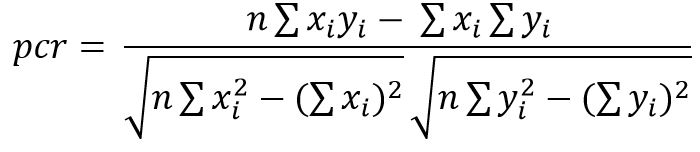
Above formula provides us the Pearson Correlation Coefficient or Score, where ‘n’ is the sample size or total number of fruits, ‘x’ and ‘y’ are the values corresponding to each fruit.
Python code for the above method:
[sourcecode language=”python” wraplines=”false” collapse=”false”]
#Dictionary of People rating for fruits
choices={‘John’: {‘Mango’:4.5, ‘Banana’:3.5, ‘Strawberry’:4.0, ‘Pineapple’:4.0},
‘Nick’: {‘Mango’:4.0, ‘Orange’:4.5, ‘Banana’:3.0, ‘Pineapple’:4.5},
‘Martha’: {‘Orange’:5.0, ‘Banana’:2.5, ‘Strawberry’:4.5, ‘Apple’:3.5},
‘Mathew’: {‘Mango’:3.75, ‘Strawberry’:4.25, ‘Apple’:3.5, ‘Pineapple’:3.0}}
from math import sqrt
#Finding Similarity among people using Eucledian Distance Formula
class testClass():
def pearson(self, cho, per1, per2):
#Will set the following dictionary if data is common for two persons
sample_data={}
#Above mentioned varibale is an empty dictionary, that is length =0
for items in cho[per1]:
if items in cho[per2]:
sample_data[items]=1
#Value is being set 1 for those items which are same for both persons
#Calculating length of sample_data dictionary
length = len(sample_data)
#If both person does not have any similarity or similar items return 0
if length==0: return 0
#Remember one thing we will calculate all the below values only for common items
# or the items which are being shared by both person1 and person2, that’s why
# we will be using sample_data dictionary in below loops
#Calculating Sum of all common elements for Person1 and Person2
sum1=sum([cho[per1][val] for val in sample_data])
sum2=sum([cho[per2][val] for val in sample_data])
#Calculating Sum of squares of all common elements for both
sumSq1=sum([pow(cho[per1][val],2) for val in sample_data])
sumSq2=sum([pow(cho[per2][val],2) for val in sample_data])
#Calculating Sum of Products of all common elements for both
sumPr=sum([cho[per1][val]*cho[per2][val] for val in sample_data])
#Calculating Person Correlation Score
x = sumPr-(sum1*sum2/length)
y = sqrt((sumSq1-pow(sum1,2)/length)*(sumSq2-pow(sum2,2)/length))
if y==0 : return 0
return(x/y)
#Value being returned above always lies between -1 and 1
#Value of 1 means maximum similarity
def main():
ob = testClass()
print(ob.pearson(choices, ‘John’, ‘Nick’))
print(ob.pearson(choices, ‘John’, ‘Martha’))
print(ob.pearson(choices, ‘John’, ‘John’))
if __name__ == “__main__”:
main()
[/sourcecode]
Output
0.6546536707079778
1.0



One thought on “Pearson Correlation Score”