

Markowitz Theory using Python
Hi ML Enthusiasts! In the previous tutorial, we learnt about Markowitz Portfolio theory. In this part 5 of our Financial Analytics series, we will learn building efficient frontier using Markowitz Theory using Python and we will also learn how we can implement this in Python. In case you’re new to this series, we suggest you go through this series from its starting point, i.e., part 1 of Financial Analytics series.
Markowitz Theory using Python – Real-life scenario
We will look at what shares and stocks profile look like in real-life. In real-life, the shares having higher expected returns have higher risk involved with them, i.e., higher standard deviation. While shares having lower expected returns have lower risk involved.
For this post, we will be used the following values corresponding to shares X and Y.
| Parameter | Share X | Share Y |
|---|---|---|
| Expected return | 9% | 11% |
| Standard deviation | 8% | 10% |
| Correlation | 20% |
After using the same methodologies and formulae that we used in our previous post, we get following table with only difference being that we use the weight steps of 10%:
| Portfolio No | Weight A | Weight B | Expected Return | Standard Deviation |
|---|---|---|---|---|
| Portfolio 1 | 100% | 0% | 9.00% | 8.0% |
| Portfolio 2 | 90% | 10% | 9.20% | 7.5% |
| Portfolio 3 | 80% | 20% | 9.40% | 7.1% |
| Portfolio 4 | 70% | 30% | 9.60% | 6.9% |
| Portfolio 5 | 60% | 40% | 9.80% | 6.8% |
| Portfolio 6 | 50% | 50% | 10.00% | 7.0% |
| Portfolio 7 | 40% | 60% | 10.20% | 7.3% |
| Portfolio 8 | 30% | 70% | 10.40% | 7.8% |
| Portfolio 9 | 20% | 80% | 10.60% | 8.5% |
| Portfolio 10 | 10% | 90% | 10.80% | 9.2% |
| Portfolio 11 | 0% | 100% | 11.00% | 10.0% |
Let’s start analyzing this by Python code.
Let’s first import all the libraries we will be needing for this analysis.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
Next, we will convert the values in Expected Return column into a list and then will pass this list to a variable, ExpectedReturn. The same will be done for StandardDeviation.
ExpectedReturn = [9.00,9.20,9.40,9.60,9.80,10.00,10.20,10.40,10.60,10.80,11.00]
StandardDeviation = [8.0,7.5,7.1,6.9,6.8,7.0,7.3,7.8,8.5,9.2,10.0]
We will now use matplotlib library of python to come up with scatter plot. We want standard deviation on x-axis and expected return on y-axis.
plt.scatter(StandardDeviation, ExpectedReturn)
plt.xlabel("Standard deviation (in %)")
plt.ylabel("Expected return (in %)")
plt.title("Markowitz Portfolio Analysis")
plt.show()
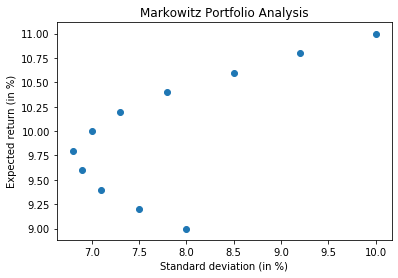
Markowitz Theory using Python – Efficient and inefficient frontiers
From above chart, we can see that for same values of standard deviation, we are getting both higher and lower values of returns – these points correspond to standard deviation of 7, 7.5 and 8, for which the curve is forming parabola – for these values of standard deviation and lower returns, the portfolios that we get are termed as Inefficient Frontier and the need is to avoid the values/points below expected return of 9.75%. All values above this value form part of efficient frontier.
Let’s now import pandas_datareader library and start implementing everything we have learnt so far.
from pandas_datareader import data as dr
We will be choosing The Procter and Gamble company and The Microsoft Corporation historical data in our analysis.
stocks = ['PG', 'MSFT']
Fetching last 10 year data – Adj Close figures for each of these companies
stock_data = pd.DataFrame()
for s in stocks:
stock_data[s] = dr.DataReader(s, data_source = 'yahoo', start = '2010-01-01')['Adj Close']
stock_data.head()
stock_data.tail()
Let’s now normalize this data and see their line charts to see their trends and compare them with each-other.
(stock_data/stock_data.iloc[0] * 100).plot(figsize = (10,8))
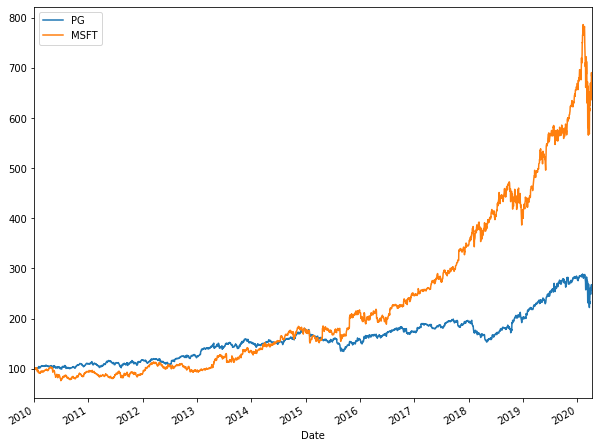
From the above chart, we can see that Microsoft had exponential growth. PG, on the other hand, took approximately had linear growth with low slope. Till 2015, PG had upper hand, after 2015, Microsoft, owing to its exponential rate, did wonders. In 2020, both saw downward trend (COVID-19 impact?).
Let’s obtain the logarithmic returns figures for both of them.
logReturns = np.log(stock_data/stock_data.shift(1))
logReturns
#To obtain annual average returns!
logReturns.mean() * 250
#To obtain annual covariance between PG and Microsoft
logReturns.cov() * 250
From above, we can see that annual average returns of Microsoft, after looking at the past 10 years data, comes out to be 18.7% while that of PG comes out to be 9.26%, just half of that of Microsoft.
The covariance of PG and MSFT is 0.0192. The autocovariance of MSFT is 0.062 and that of PG is 0.029.
Let’s now compute the correlation matrix for both of them.
stock_data.corr()
From above, we can see that there is fair amount of relationship of 92.5% (>30%) between PG and MSFT.
Let’s now start creating efficient frontier.
# Dynamically generating weights code
numberOfStocks = len(stocks)
numberOfStocks
# Creating random weights
# Function random of numpy will generate two floats
weights = np.random.random(numberOfStocks)
weights
weights.sum()
weights = weights/np.sum(weights)
weights
weights.sum()
We see that weights array has sum equal to 1 or 100%. The weight of first stock, i.e., PG will be set as 16.92% and that of MSFT will be set as 93.35%.
Calculating expected return of portfolio
(weights * logReturns.mean()).sum() * 250
Thus, the expected return of the portfolio with these weights comes out to be 17.09&
Expected standard deviance or volatility
np.sqrt(np.dot(weights.T, np.dot(logReturns.cov() * 250, weights)))
We can see that the standard variance or volatility of the portfolio comes out to be 22.13% which is very high.
Simulation with same stocks but different weights
We are doing this simulation to find out the most optimum sets of weights for which standard deviation or volatility comes out to be minimum and expected return comes out to be maximum. Let’s do this for 100 different sets of weights first.
#Creating blank lists
expectedReturn = []
standardDeviation = []
weightList0 = []
weightList1 = []
# Running simulations for finding optimum weights
for i in range(100):
weights = np.random.random(numberOfStocks)
weights = weights/ weights.sum()
weightList0.append(weights[0])
weightList1.append(weights[1])
expectedReturn.append((weights * logReturns.mean()).sum() * 250)
standardDeviation.append(np.sqrt(np.dot(weights.T, np.dot(logReturns.cov() * 250, weights))))
#Converting lists into arrays
weightList0 = np.array(weightList0) #Weights for PG
weightList1 = np.array(weightList1) #Weights for MSFT
expectedReturn = np.array(expectedReturn)
standardDeviation = np.array(standardDeviation)
#Creating dataframe
df = pd.DataFrame({"Weight of PG": weightList0, "Weight of MSFT": weightList1, "Expected Return": expectedReturn, "Standard deviation": standardDeviation})
df.head()
Let’s now plot this on a scatter chart
plt.figure(figsize=(14, 10), dpi=80)
plt.scatter(df["Standard deviation"], df["Expected Return"])
plt.xlabel("Standard deviation")
plt.ylabel("Expected return (in %)")
plt.show()
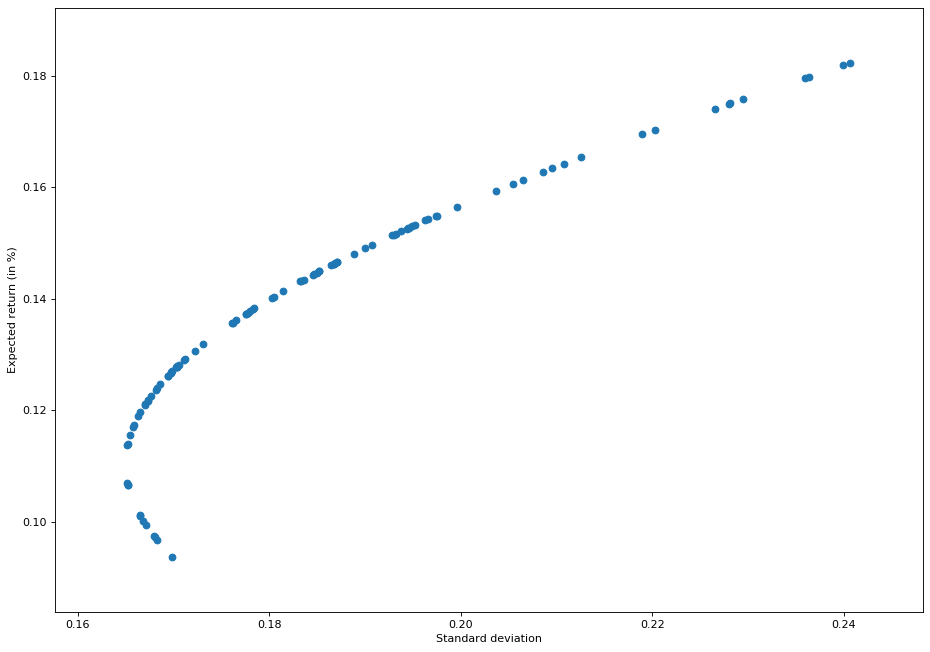
From above chart, we see that values above the expected return of 0.11 or 11% correspond to the efficient frontier and those below 11% correspond to inefficient frontier.
The above chart also states the same thing – if you want greater return, you will have to take greater risk! If you’re risk averse person, then take the values of weights corresponding to expected return of 11%. Let’s see what are the values corresponding to them.
df[(df["Expected Return"]>0.11) & (df["Expected Return"]< 0.12)].sort_values(by=['Expected Return'])
df[(df["Expected Return"]>0.11)].sort_values(by=['Expected Return']).head(10)
Thus, we can see that in case of efficient frontiers, for expected return of 11.37%, the standard deviation is 16.52% which corresponds to weight of 77.56% of PG and 22.43% of MSFT shares.
Finding most optimum portfolio
df["Expected Return"].mean()
df["Expected Return"].sort_values().median()
df[(df["Expected Return"]>0.135)].sort_values(by=['Expected Return'])
df.loc[63]
df.loc[49]
Going by both mean and median of efficient frontiers, we can see that Weight of PG varies from 51.57% to 49.57% and that of MSFT varies from 48.42% to 50.42%. This variation leads to expected return from 13.82% to 14.01% with volatility from 17.84% to 18.02%.
The point worth to be mentioned over here is that the volatility of MSFT is higher than that of PG. PG is more stable than MSFT. So, as we go from reducing PG weights and increasing MSFT weights, we are not only increasing returns, we are also increasing volatility of portfolio.
So guys, with this we conclude this tutorial on Financial Analytics. In the next part, we will be diving deeper into the world of Financial Analytics. Stay tuned!


